这个现象很奇怪,首先看一下下面两张图。第一章是首页的,明显可以看到有一条未读文章:
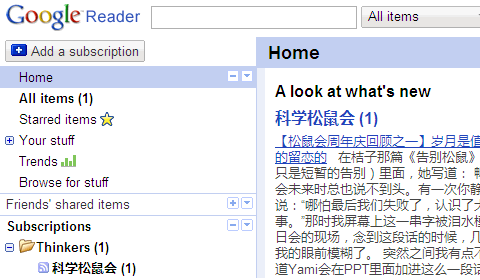
好,现在点进去看看:
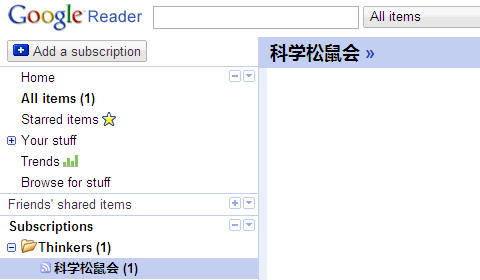
发现了吧?一片空白,就连阅读辅助工具栏都出不来了。很奇怪,只有这个订阅有问题,其他的都是好的,而且这个源已经更新很多篇文章了,但是在我的这里显示的一直是这篇文章。后面更新的文章全部没有,有谁知道这是怎么回事吗?…
这个现象很奇怪,首先看一下下面两张图。第一章是首页的,明显可以看到有一条未读文章:
好,现在点进去看看:
发现了吧?一片空白,就连阅读辅助工具栏都出不来了。很奇怪,只有这个订阅有问题,其他的都是好的,而且这个源已经更新很多篇文章了,但是在我的这里显示的一直是这篇文章。后面更新的文章全部没有,有谁知道这是怎么回事吗?…
做这个的起因很简单:我喜欢用Google Chrome,又喜欢逛豆瓣,Google Chrome支持User Scripts了,但是我写的那几个插件在Chrome下又跑不了。因为Google Chrome有Google Gears,据说可以跨域Ajax,于是弄吧!结果越弄越复杂,因为Google Gears的跨域也是有很多限制的,看来还得服务器跑,还好有Google的App Engine,继续弄下去吧!
当然了,现在这个仅仅只是为Google Gears服务,写的很简单,不过还是比较“Ajax”的,看看简单的示例代码:
<script type="text/javascript" src="gears_init.js"></script>
<script type="text/javascript">
var options = … 今天在玩JavaScript的语法高亮,弄得差不多了在Firefox 3和IE 7下都正常了,最后想看看Chrome下是不是正常,结果打开我的测试页面,除了在前面的一部分文字显示出来以外,页面剩余部分居然是一片空白!
很诡异的用chrome打开源代码看(因为有语法高亮,很容易知道问题出在哪),结果很明显,我的js中有这么一句:
this.ignore = '<!--';
在源代码查看器中显示,Chrome从这个注释字符串开始,把后面的都当成注释了,偏偏我后面的js里面还有这么一行:
this.commentOff = '-->';
由于这一段js被chrome认为是注释,以致页面不能正常解析,所以这个字符串前面的HTML代码能够正常工作,而这个后面的就不行了……
不过有一个解决办法,就是把这段js写在外部文件中就没这个问题了^_^…
最近继续用Google Reader,看到好的blog还是会继续添加RSS到Google Reader,用Chrome的时候才发现这个怪事,自家人不认自家人了:
第一步:点这个按钮:
第二步:添加到Google Reader,注意URL的参数也是正确的: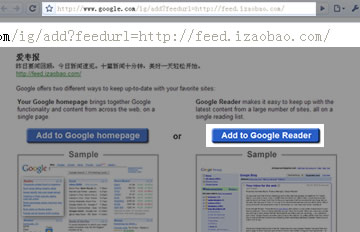
第三步:Failed了……这个时候的参数还是正确的: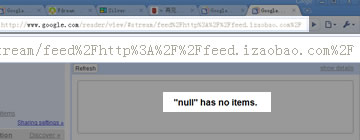
这几步在Firefox下却没有任何问题,看来仅仅只有速度还不行啊,也要保证可用性才好。…
初看Chrome的界面,实在是太简陋了,甚至可以说有点丑,不过这也符合Google的一贯风格,简洁。看了这界面,貌似也没有特别的功能,本来没准备安装的,直到看了这一系列的漫画,其中有介绍说Chrome是每个Tab一个进程,当一个Tab崩溃的时候,不会导致整个浏览器崩溃,而且可以完全回收该Tab所占用的内存,这一点比Firefox可是强多了,不必每次用浏览器用久了就需要重启一下浏览器,以清理内存。于是决定装了,不过据观察,貌似这一点IE 8已经做了,在试用IE 8的过程中,浏览器经常停止工作,但是实际上IE 8仍然可以继续用,而当某个Tab崩溃的时候,IE 8还能够自动恢复这个Tab,有此看来,Firefox需要加油了!
主界面,的确很简洁,我很喜欢: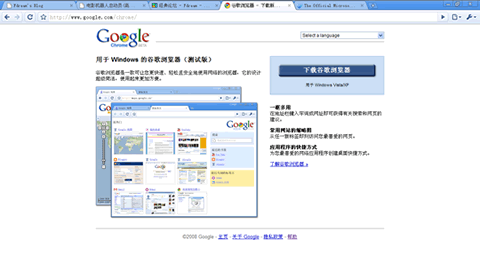
是否保存密码,和IE 8、Firefox 3一样: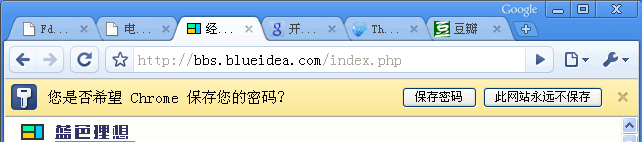
插件支持,号称支持包括Flash、Acrobat Reader、Java、Windows Media Player、Real…
Google App Engine申请到手好长时间了,一直没有管,今天无聊,弄了两个页面传上去,一个是Helloworld级别的,一个是自带的Demo(我就改了一下路径)。访问地址:http://1986.appspot.com
发现好多人用Google App Engine写tracker(p2p要用的),真是不错的主意,因为本身Google App Engine可以提供高效的数据检索(GQL:Google Query Language)和强大的负载均衡能力,正好适合这种大应用。
为了充分利用Google App Engine的强大能力,我在想是不是用这个来作一些基于WebService的服务,可是做什么好呢?大家有木有什么好的主意咧?
PS: Google App Engine只支持Ptyhon,同时出于安全性考虑,暂不支持C扩展。另外,在Windows Vista下貌似不能玩,偶没有XP,不得不开虚拟机换到Fedora下………
看了一下blog得来访统计,在从搜索引擎来源的关键字中,发现有些关键字与当前的十七大气氛极不和谐,而这些不和谐的关键字竟然全部都是从百度过来的!
在最近的200条记录中,来自百度的有39条,其中的非和谐关键字达23条之多,而大部分都是与“成人光碟”有关的,例如:
成人dvd光碟专卖 (6次)
成人光碟专卖 (3次)
看成人光碟vcd (2次)
成人dvd光碟下载 (2次)
成人光碟dvd专卖
难道我的上面有不和谐的信息?看了看来源页面,发现都是原来blog上的垃圾评论,顺着搜索结果过去,我现在的页面上当然早已经没有这些垃圾评论了,于是再看看百度快照,发现了一个奇怪的现象:百度快照上的结果显示该垃圾评论是2006年12月23日发表的,而当时我并没有注册fdream.net!为什么百度快照会出现这样的结果?
来自百度的用户也有一些是通过技术类的关键字过来的,比如:silverlight退出全屏、运行命令解决http500错误(我不明白是什么意思……)等。也有一些很有趣的关键字,比如:那个可以给我24点最难的题目(这家伙看来是24点无敌了,可以试试偶的…
一直没有用过Google Books,趁休息到处上网乱逛,看到Google的更多菜单里有一个Books,于是过去试了试,正好要找一些WPF的书看看,于是把“WPF”三个字敲进去,回车,结果真是很令我吃惊:居然有这么多书!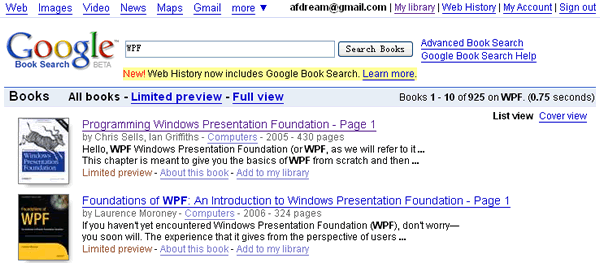
另外,这些书你可以添加到你的收藏里面,然后在线阅读,很不错,嗯!
在阅读的时候,你可以在书里面进行搜索,输入关键字就可以了,这样就不用把眼睛瞪得老大然后在目录里面找了,哈哈……
PS:貌似默认是中文版的,老是出问题,建议使用英文版的Google,访问google.cn,然后点首页下面的那个“Google.com in English”就可以了^_^…
上了Gmail,发现右上角有个醒目的链接“Watch Our Video”,点过去一看,原来是一段关于Gmail是怎样传送的视频。视频中的人物都是各显身手,绝技不断,很有些意思,可以看看哦~
视频播放地址:http://www.youtube.com/watch?v=VfDW7qAdFGk
(nnd,才发现我的BLOG没有插入视频功能……)…
 标题有点大,但是这是我N次看到我的收藏夹里一溜的google图标惟一想说的。
标题有点大,但是这是我N次看到我的收藏夹里一溜的google图标惟一想说的。
很多兄弟奇怪,你的收藏夹里怎么这么多google?是的,我的收藏夹里为什么有这么多google呢?都够我单独为其再建一个收藏菜单了,命名为google。我说,原因很简单,我喜欢google的这些服务!尽管Google的搜索我用的不多,这有三个原因:
第一:最重要的一个原因就是网页快照不能用,而我在搜索的时候绝大多数情况下使用快照,更容易找到目标。
第二:我用的是教育网,Google的搜索结果中有很大一部分我无法访问。这一点和第一点是我不用google的致命性问题。
第三:google的中文搜索的确不如百度,尽管百度是个英文文盲。
但是我仍然收藏了google的首页,因为首页是google绝大部分服务的入口,而且还能从首页上不时发现一些意外。比如今天,发现google的个性化主页又增新功能:支持标签(Tab)。这也正是我收藏这么多…